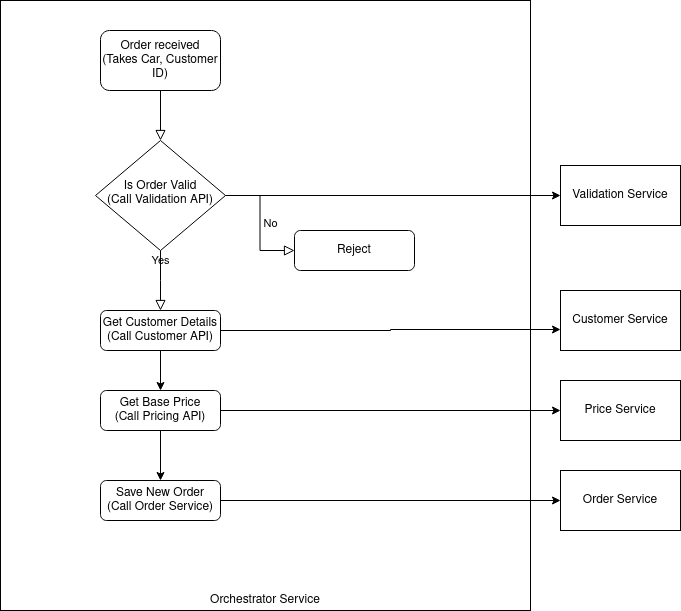
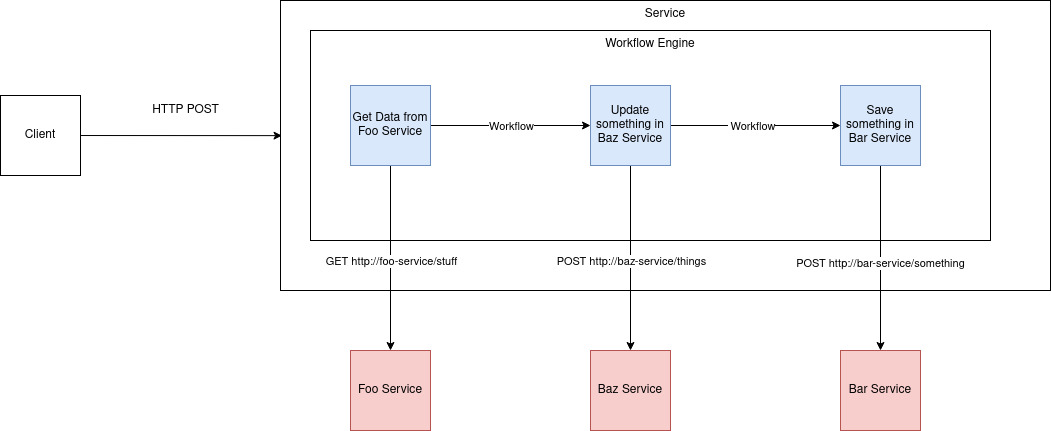
Thoughts from JUXT's XT26 Conference - Part 2

Final Summary / Thoughts Once again I am reminded how great it is to "step back and look at the bigger picture" every once in a while. XT26 gave me the opportunity to do that. It's so great to extract yourself from the day to day and hear the thoughts of such great thought leaders all in the same room. It was also fantastic to reconnect with old friends and colleagues. Thanks so much to JUXT for putting this on - I had high expectations and was not disappointed!